
Connected everything is the buzz these days. There are varieties of use cases that will affect our daily lives. The connected car is an example of the Internet of Things (IoT) that many are watching and are curious about how it will work. Part of solving the system needs for this requires significant compute and storage resources that can scale instantly. The need is to support data exchange between vehicles and the rest of the connected world. This blog post presents an example of how to assemble specific services from Amazon Web Services (AWS) to accomplish a serverless solution.
Serverless refers to managed software services that you install your application code into that will run securely in virtual containers. They can consume the amount of resources needed on demand. When the load decreases, underutilized resources terminate so someone else can use them until you need them again. This way you have the compute and storage capacity you need at any point in time. As a result, your cost matches exactly what you consume. The increment for compute resources (CPU and memory) for AWS Lambda in this case is 100 milliseconds and as a result, costs track actual usage very closely. Storage costs with DynamoDB follow a similar concept where you only pay for how much data you store and how fast you want to read and write with it.
The goal for my project (Car2Cloud) is to connect my vehicle to AWS cloud services to track driving characteristics and potential vehicle faults.
The high level requirements are to:
- Access public cloud (AWS) connectivity
- Leverage complete serverless concepts
- Automate data collection and reporting
The diagram below is the high-level architecture for my prototype and uses a small computer in the car to collect and report data to the AWS IoT service which stores the data in DynamoDB. A simple static web site is hosted on S3 that accesses the data to provide visualizations.
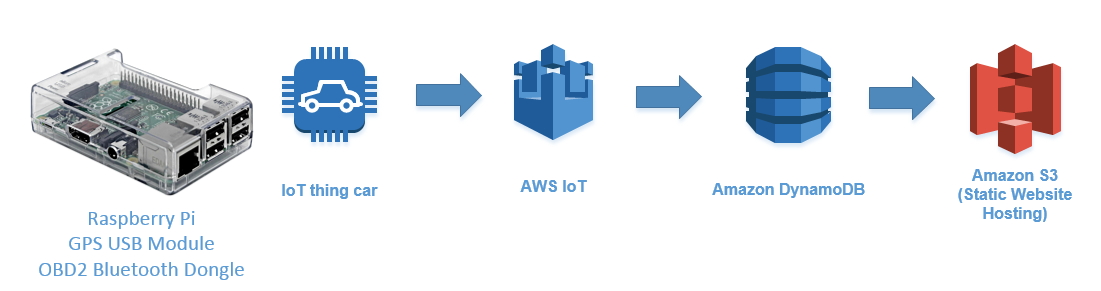
The “device” computer is a Raspberry PI 3 with a Bluetooth OBD-II interface and USB GPS module. Wi-Fi is available on the board to establish internet connectivity with my home network. An optional smartphone hotspot connection enables a real-time reporting and tracking.
The headless device runs a Python program on startup that polls the vehicle engine control unit (ECU) for various data. Python-OBD is the library used to communicate with the Bluetooth dongle. Each vehicle supports a variable number of parameter ID (PID), but basic ones include RPM, Speed, etc. I setup polling for every 500 milliseconds and combine that data with the GPS position information to form a complete JSON message (see code snippet below). ECU communication states are part of the solution to know if the vehicle is on. Support for different vehicle and network states include:
- Vehicle on, Network Connected (driving with a hotspot)
- Vehicle on, Network Disconnected (driving without a hotspot)
- Vehicle off, Network Connected (parked at home)
- Vehicle off, Network Disconnected (parked somewhere away from home)
The program sends JSON Messages using the AWS SDK to the IoT service using the MQTT protocol when the device authenticates again. A very handy feature of the SDK’s client connection is that it supports buffering of messages when network connectivity is lost. It can be configured to queue messages on a first-in-first-out (FIFO) basis or unlimited. When connectivity exists, any buffered messages relay automatically to the cloud.
[...]
while (True):
if not car_talking(car):
#try to reconnect to the car
time.sleep(10)
car_connect()
if lastCarMsgState and car.is_connected():
myCarReport = {
'vin' : "123456abcdef",
'ts' : datetime.datetime.utcnow().isoformat(),
'gps_lat' : gpsd.fix.latitude,
'gps_lng' : gpsd.fix.longitude,
'gps_altitude' : gpsd.fix.altitude,
'gps_speed' : gpsd.fix.speed,
'engine_load' : obd_utility.getOBD(car, obd.commands.ENGINE_LOAD),
'coolant_temp' : obd_utility.getOBD(car, obd.commands.COOLANT_TEMP),
'rpm' : obd_utility.getOBD(car, obd.commands.RPM),
'speed' : obd_utility.getOBD(car, obd.commands.SPEED),
'timing_advance' : obd_utility.getOBD(car, obd.commands.TIMING_ADVANCE),
'intake_temp' : obd_utility.getOBD(car, obd.commands.INTAKE_TEMP),
'maf' : obd_utility.getOBD(car, obd.commands.MAF),
'throttle_pos' : obd_utility.getOBD(car, obd.commands.THROTTLE_POS),
'run_time' : obd_utility.getOBD(car, obd.commands.RUN_TIME),
'distance_w_mil' : obd_utility.getOBD(car, obd.commands.DISTANCE_W_MIL),
'fuel_level' : obd_utility.getOBD(car, obd.commands.FUEL_LEVEL),
'barometric_pressure' : obd_utility.getOBD(car, obd.commands.BAROMETRIC_PRESSURE),
'absolute_load' : obd_utility.getOBD(car, obd.commands.ABSOLUTE_LOAD),
'relative_throttle_pos' : obd_utility.getOBD(car, obd.commands.RELATIVE_THROTTLE_POS),
'ambiant_air_temp' : obd_utility.getOBD(car, obd.commands.AMBIANT_AIR_TEMP)
}
try:
myAWSIoTMQTTClient.publish("car2cloud", json.dumps(myCarReport), 1)
logger.debug(json.dumps(myCarReport))
except:
logger.warning("exception while publishing")
try:
myAWSIoTMQTTClient.connect()
except:
pass
time.sleep(0.5)
[...]The setup of the IoT service involves registering the device, generating security credentials and applying a policy. The installed certificate on the device establishes a connection with the AWS IoT service. Note there are best practices to perform automated device registration when running a system at full scale.
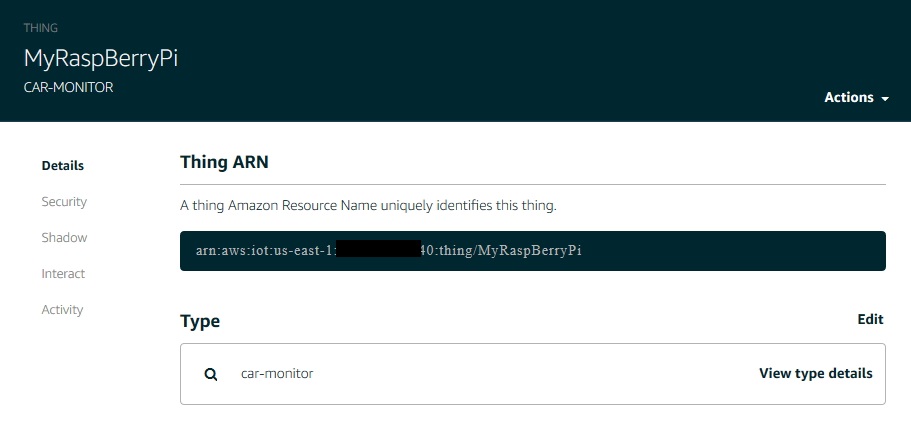
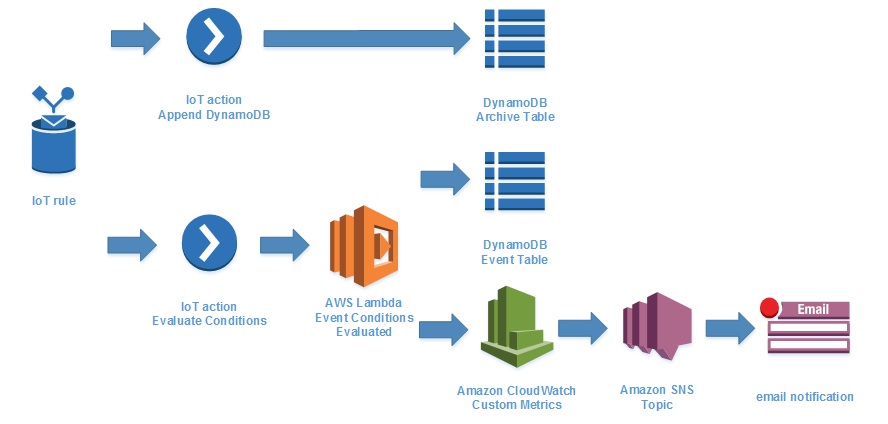
AWS storage services receive filtered message data in the cloud. In my prototype, I separate the various attributes of the JSON message and store them as separate columns within a DynamoDB table for trend analysis and visualization. I also evaluate certain data to assess different conditions and record those in another table for use in raising alerts. The diagram below shows details of how to configure the IoT service to support these needs.
The configuration involves adding an IoT Service Rule that selects all messages and forks them to two different actions. The first action automatically separates the message attributes and stores them in a designated DynamoDB table.
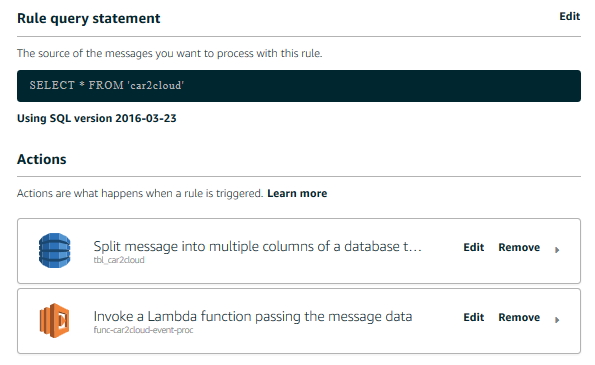
The service automatically separates out the data attributes from the message and stores them as columns in the table. DynamoDB is a highly scalable No-SQL database service that integrates easily with most other services in AWS. New data columns are automatically added which is a benefit. This supports the need to be flexible when connecting too many kinds of vehicles, each of which will support a variable list of OBD-II PID values.
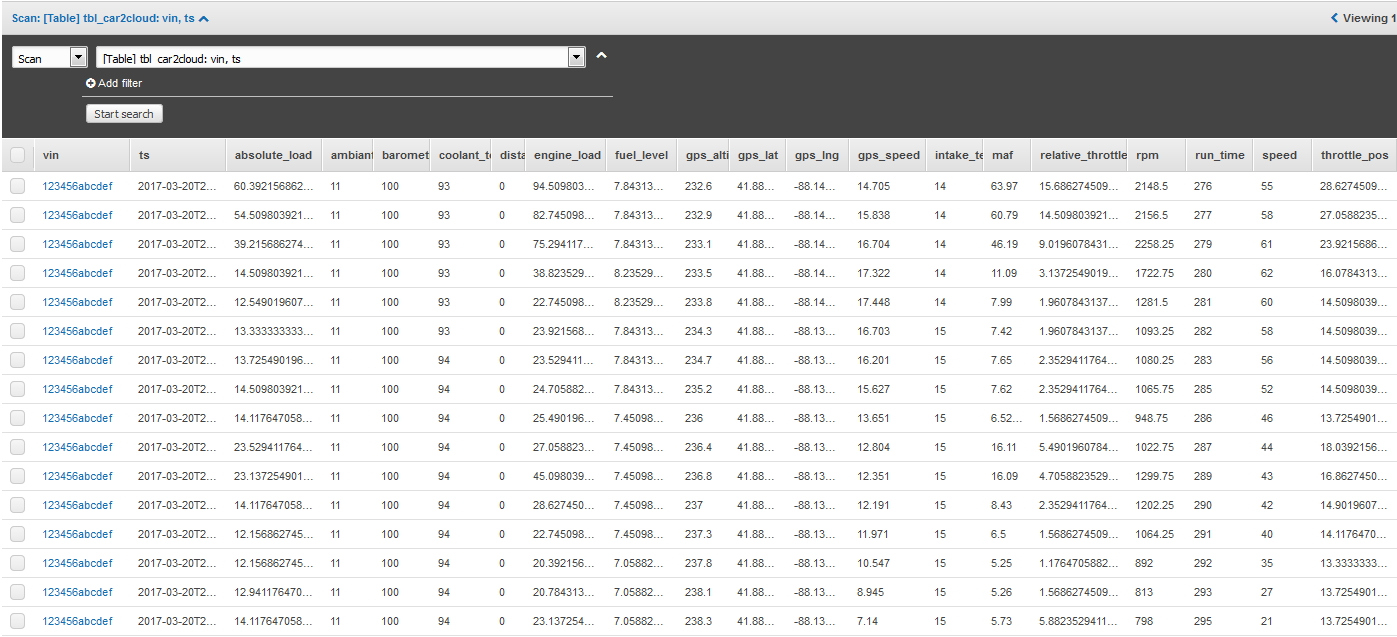
The second action invokes an AWS Lambda function that evaluates each message received. Established conditions apply certain logic that are recorded as events in a second DynamoDB table. As the other services described so far, Lambda is another serverless way to run stateless functions in the cloud. A Python function uses the Boto3 library to access the AWS SDK. The “event” parameter contains the JSON message from the IoT service and looks for conditions that are translated into event topics I have defined. Those are stored in the second DynamoDB table.
I also incorporate a customer metric in AWS Cloudwatch where an alert is configured to send an email notification via an AWS SNS Topic. In this simple example, the custom metric records a value of 0 or 1 representing the fuel level state. When the fuel level goes low, an email is sent.
import boto3
def lambda_handler(event, context):
event_name = ""
# test for high rpm
if event['rpm'] > 2700 :
event_name = "High RPM"
#test for high absolute load
if event['absolute_load'] > 97 :
event_name = "High Engine Load"
if event_name != "" :
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('tbl_car2cloud_events')
response = table.put_item(
Item={
'vin': event['vin'],
'ts': event['ts'],
'event': event_name
}
)
#check fuel level and add cloudwatch metric which will trigger an alarm/email
if event['fuel_level'] < 5 :
fuel_state_low = True
else:
fuel_state_low = False
client = boto3.client('cloudwatch')
response = client.put_metric_data(
Namespace='car2cloud',
MetricData=[
{
'MetricName': 'low_fuel_level',
'Timestamp': event['ts'],
'Value': fuel_state_low,
'Unit': 'Count'
}
]
)
Visualization is accomplished using the AWS S3 service and the static web site feature that can be enabled on a bucket. S3 provides a fast and reliable way to store files where access can be opened up to anyone and is another serverless component of the solution. To make the content dynamic, Javascript is used to connect to DynamoDB using AWS Cognito Unauthenticated Identity Pool access. The IAM policy associated with this Identity Pool is restricted to allow read access to only the table that is needed.
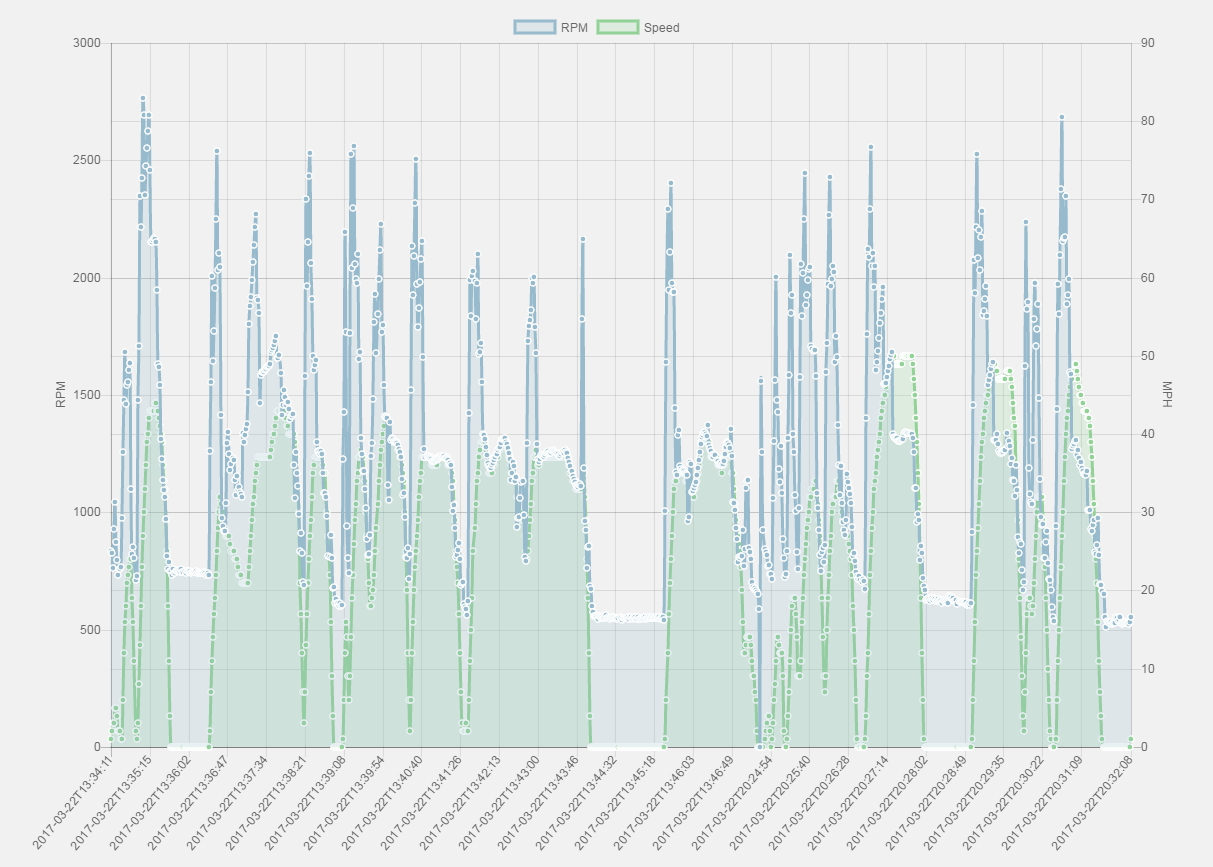
The chart visualization uses the Chart.js library that is setup to show the last two-days of data received. Vehicle Speed and RPM are displayed and updated upon refresh.
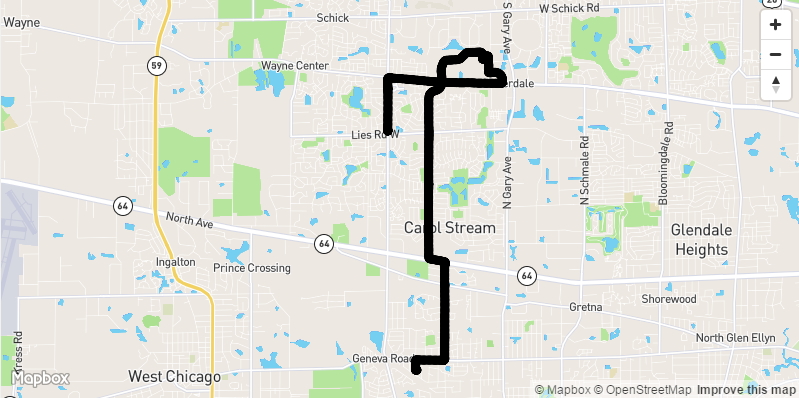
Location is shown using the Mapbox GL library for the same data in the chart. Latitude and Longitude data is converted to a GeoJSON format and then dynamically loaded on the map.
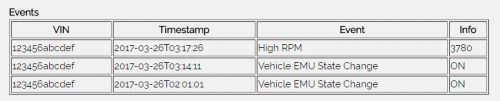
The Lambda function detects events and stores them in a DynamoDB table. They web site then displays them for review.
In summary, the prototype is an example of how to accomplish serverless computing in the cloud. With this solution, you only pay for the volume of IoT messages sent. You have access to a storage database that can scale to an unlimited size, but only pay for how much data stored. You can apply business logic and rules in parallel as data arrives and pay for the time the process runs. You only pay for the custom metrics created and for the corresponding notifications. The web site cost is only for the size of the HTML files stored in the cloud. These types of services provide opportunities to drive down operating expenses for compute and storage while improving the availability of your application. It also has the added benefit of decoupling and simplifying your architecture to support future growth in your business.

Hi Kevin,
Found your blog really nice.
Just one ask, the first function where you are doing a looping funtion to send stats like gps and obd utility available one’s, where are you configurng the AWSTOMQTT client before publishing the Jon ?
Also what exactly are you doing under car_connect and car_talking ?
May be full function definition can make better understanding .